Python3处理HTTPS请求 SSL证书验证
金融类的公司网站一般都是https 开头的网站,urllib.request可以为 HTTPS 请求验证SSL证书,就像web浏览器一样,如果网站的SSL证书是经过CA认证的,则能够正常访问,如:
- 平安好伙伴出单系统:
- 浙商保险出单系统:
例子一:编写一个https请求程序访问(平安好伙伴出单系统)
from urllib import parse
import urllib.request
url = 'https://icore-pts.pingan.com.cn/ebusiness/login.jsp'
headers ={
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.139 Safari/537.36",
}
# url 作为Request()方法的参数,构造并返回一个Request对象
request = urllib.request.Request(url,headers=headers)
# Request对象作为urlopen()方法的参数,发送给服务器并接收响应
response = urllib.request.urlopen(request)
html = response.read().decode('utf-8')
print(html)

通过例子,是可以正常访问的,因为网站的SSL证书是经过CA认证的。
如果SSL证书验证不通过,或者操作系统不信任服务器的安全证书,比如浏览器在访问12306网站如:https://www.12306.cn/mormhweb/的时候,会警告用户证书不受信任。(据说 12306 网站证书是自己做的,没有通过CA认证)
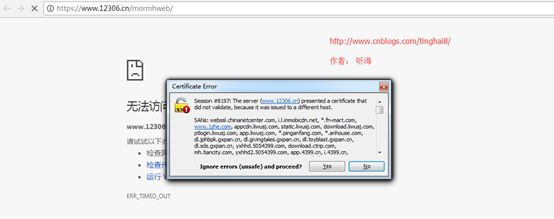
例子二:编写一个https请求程序访问(12306网站)
from urllib import parse
import urllib.request
url = 'https://www.12306.cn/mormhweb/'
headers ={
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.139 Safari/537.36",
}
# url 作为Request()方法的参数,构造并返回一个Request对象
request = urllib.request.Request(url,headers=headers)
# Request对象作为urlopen()方法的参数,发送给服务器并接收响应
response = urllib.request.urlopen(request)
html = response.read().decode('utf-8')
print(html)
运行结果:
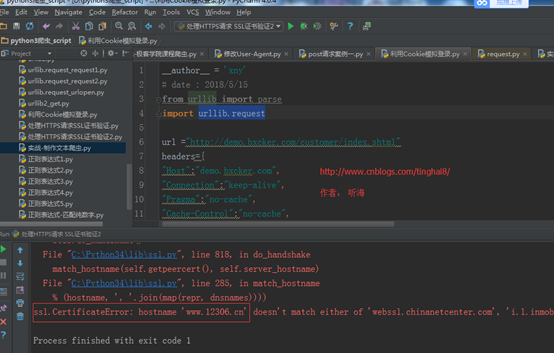
运行报错:ssl.CertificateError: hostname 'www.12306.cn' doesn't match either of 'webssl.chinanetcenter.com'
通过查看urllib.request库源码文件

如果网站的SSL证书是经过CA认证,就需要单独处理SSL证书,让程序忽略SSL证书验证错误,即可正常访问。
例子三:12306网站或略SSL证书验证
from urllib import parse
import urllib.request
# 1. 导入Python SSL处理模块
import ssl
# 2. 表示忽略未经核实的SSL证书认证
context = ssl._create_unverified_context()
url = 'https://www.12306.cn/mormhweb/'
headers ={
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.139 Safari/537.36",
}
# url 作为Request()方法的参数,构造并返回一个Request对象
request = urllib.request.Request(url,headers=headers)
# Request对象作为urlopen()方法的参数,发送给服务器并接收响应
# 3. 在urlopen()方法里 指明添加 context 参数
response = urllib.request.urlopen(request,context = context)
html = response.read().decode('utf-8')
print(html)
运行结果:
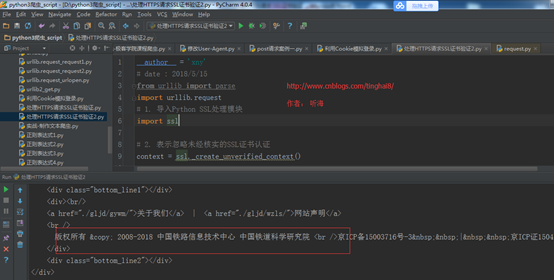
通过例子,证明我们的处理是成功的。